根据最新公布的 MLPerf 基準测试结果,NVIDIA 的合作伙伴目前提供用于训练人工智慧 AI 的 GPU 加速系统,其速度较任何系统更快。

七间公司在最新一轮的产业基準测试中,提交至少十多套市售系统进行测试,其中大多为 NVIDIA 认证系统。NVIDIA 与戴尔 (Dell)、富士通 (Fujitsu)、技嘉 (GIGABYTE)、浪潮 (Inspur)、联想 (Lenovo)、宁畅 (Nettrix) 及美超微 (Supermicro) 共同展示了使用 NVIDIA A100 Tensor 核心 GPU 训练神经网路,所创造出引领业界的亮眼表现。
只有 NVIDIA 及其合作伙伴完整进行最新一轮基準测试中的八项作业负载。整体来说,搭载 NVIDIA 技术的提交资料共占了四分之三以上,且结果十分漂亮。
与去年的成绩相比,NVIDIA 的效能表现提升了 3.5 倍。针对需要使用庞大运算资源的大规模作业,我们从破纪录的 4,096 个 GPU 中集结资源,较任何其他参与测试的产品都还要更多。
MLPerf 为何如此重要
这是 NVIDIA 商业生态系第四度参加 MLPerf 训练测试,也是表现最为亮眼的一次。MLPerf 为 2018 年 5 月成立的产业基準测试组织。
MLPerf 的测试成果让用户能在充分了解的情况下进行购买决策,并获得数十间业界领导者的支持,包含阿里巴巴、Arm、百度、Google、英特尔 (Intel) 与 NVIDIA 等,其测试结果兼具透明性和客观性。
这项测试基準以目前最热门的 AI 作业负载和场景为基础,涵盖电脑视觉、自然语言处理、推荐系统、强化学习等,而训练基準则聚焦于用户最为关心的事情,也就是训练一个全新 AI 模型所需耗费的时间。
速度加上弹性造就生产力
最终,客户基础设施投资的回报取决于他们的生产力。这来自于在运行多种 AI 作业负载时既快速又灵活的能力。
因此,这就是为什么使用者需要一套灵活且强大的系统,能够快速将各种 AI 模型投入生产环境并缩短上市时间,同时彻底发挥宝贵的资料科学团队的生产力。
根据最新的 MLPerf 测试结果,NVIDIA AI 平台在商用 AI 超级电脑类别的所有八项基準测试中以最短的时间训练模型,创下了效能记录。
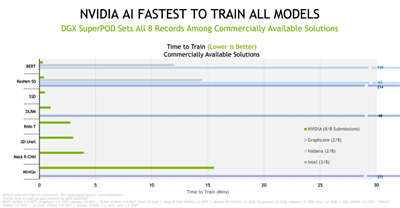
图一_NVIDIA 基于 NVIDIA DGX SuperPOD 的 Selene 系统在商用系统上创造八项记录
根据最新的 TOP500 排名,我们在当今世界上最快的商用 AI 超级电脑 Selene 上进行大规模测试。Selene 超级电脑与排行榜上其它十多套系统一样,皆採用 NVIDIA DGX SuperPOD 架构。扩展到大型丛集的能力是 AI 领域最艰鉅的挑战,也是我们的核心优势之一。
在晶片对晶片的比较中,NVIDIA 及合作伙伴在最新的商用系统测试中创造八项基準测试的纪录。
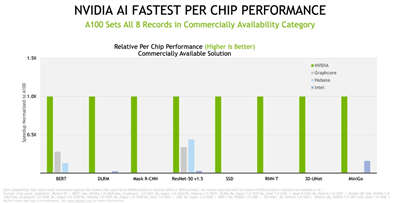
图二_A100 在商用系统类别中创下了八项全纪录
整体来说,下方的测试结果显示我们的效能在两年半内提升了 6.5 倍,这证明了可以在 GPU、系统和软体的全堆叠 (full-stack) NVIDIA 平台上进行作业。
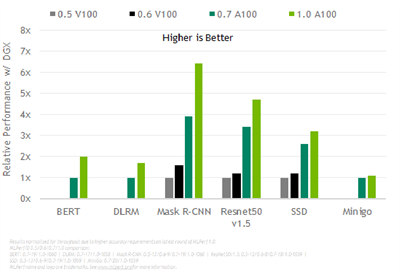
图三_NVIDIA AI 透过全堆叠的改善带来持续的效能提升
广泛的生态系提供最佳价值和选择
MLPerf 结果展示了各种基于 NVIDIA 的 AI 平台,以及许多创新系统的效能,包含从入门的边缘伺服器到搭载数千个 GPU 的 AI 超级电脑。
参与最新基準测试的近二十家云端服务供应商和 OEM 厂商,NVIDIA 的七个合作伙伴名列其中,其本地端的产品或计画採用 NVIDIA A100 GPU 的云端执行个体、伺服器和 PCIe 卡中,包括近 40 个 NVIDIA 认证系统。
我们的合作伙伴生态系为客户提供广泛的部署模型选择,从按分钟出租的执行个体到本地端的伺服器和託管服务,皆提供业内最高的价值。
所有 MLPerf 的测试结果都显示了我们的效能持续在提升,这是因为我们的平台拥有成熟且不断进化的软体,让团队可以快速开始使用持续精进的系统。
我们是如何做到的
这是我们 A100 GPU 第二次参与 MLPerf 测试。在另一篇文章中,详细描述了 GPU、系统、网路与 AI 软体等方面的进步如何提升运算速度。
举例来说,我们的工程师找到了一种使用 CUDA Graphs 启动全神经网路模型的方法,CUDA Graphs 是一套由 NVIDIA CUDA 运作项目及其依赖项目构成的软体套装。如此一来便消除过去测试时 CPU 遇到的瓶颈,这些测试将 AI 模型作为许多单独元件 (kernel) 的链来进行释放。
此外,大规模测试使用 NVIDIA SHARP,该软体可以整合网路交换器中的多项资料传输作业、减少网路流量与等待 CPU 处理的时间。
结合 CUDA Graphs 与 SHARP,使得资料中心可以运用破纪录的 GPU 数量来进行训练工作。这是如自然语言处理等许多领域所需要使用到的运算能力,在这些领域里的 AI 模型规模持续成长,其包含数十亿个参数。
其他优势包含最新的 A100 GPU 将记忆体频宽增加近 30%,达到每秒超过2 terabytes (TB) 的记忆体频宽。
来自客户对于 MLPerf 的回馈
各类型的 AI 用户皆认为这些基準测试为其带来实质的帮助。
瑞典 Chalmers University 的发言人表示:「MLPerf 基準测试提供针对多个跨 AI 平台且清楚的同类型比较,以展现其应用于各种真实案例的实际效能表现。」该大学进行从奈米技术到气候研究等领域的研究工作。
这些基準帮助使用者找到能够满足全球部分规模最大、最先进工厂所要求的 AI 产品。例如,全球顶尖晶片製造商台积电,使用机器学习来提升光学邻近效应修正功能 (OPC) 与蚀刻模拟 (etch simulation) 的表现。
台积电 OPC 部门主管 Danping Peng 表示:「为了充分发挥机器学习在模型训练和推论的能力,我们与 NVIDIA 工程团队合作,将 Maxwell 模拟与反向微影技术引擎转移到 GPU 上,并看见执行速度大幅提升。MLPerf 基準测试是协助我们做出决定的一项重要因素。」
在医学与製造领域逐渐受到青睐
这些基準也有助于研究人员突破 AI 的极限,以提升医疗保健水準。
德国癌症研究中心 DKFZ 的医学影像运算部门负责人 Klaus Maier-Hein 表示:「我们与 NVIDIA 密切合作,将 3DUNet 等创新技术带入医疗保健市场。产业标準的 MLPerf 基準测试提供相关的效能资料,让 IT 组织和开发人员能够取得精确的解决方案,以加速推动其特定专案和应用项目。」
全球研究与製造领域的领导者三星电子 (Samsung),在导入 AI 的过程中採用 MLPerf 基準测试,以提高产品效能及製造生产力。
三星电子的发言人表示:「我们必须具备最佳的运算平台,才能将先进的 AI 技术加以产品化。MLPerf 基準测试提供一个公开且直接的评估方法,让我们能够统一评估各平台供应商,进而简化选择的过程。」
取得相同的测试结果和工具
MLPerf 的资料储存库提供最新测试所使用的各套软体,因此,所有人皆可重现我们的基準测试结果。我们会持续将这些程式码加入深度学习框架和容器中,使用者可以在 NVIDIA 的 GPU 应用程式软体中心 NGC上取得。
它是全堆叠 AI 平台的一部分,经过最新的产业基準验证,并且能够从各个合作伙伴取得,用以处理当前真正的 AI 工作。



















